






















OpenAI o1-Preview vs Qwen QwQ-32B: Ein Logiktest-Vergleich
Find AI Tools in second
Find AI Tools No difficulty
No complicated process
Find ai tools
No difficulty
No complicated process
Find ai tools


Table of Contents
- Kernpunkte des Vergleichs
- Der Logiktest: Das Mysterium der sieben Artefakte
- Der Vergleich: Geschwindigkeit, Transparenz und Argumentation
- Verwendung von Qwen QwQ-32B für anspruchsvolle Logiktests
- Die Vor- und Nachteile von OpenAI o1-Preview
- Häufig gestellte Fragen (FAQ)
- Verwandte Fragen zur KI-Entwicklung
Der Logiktest: Das Mysterium der sieben Artefakte
Was ist der Logiktest?
Der verwendete Logiktest ist ein komplexes Rätsel, das die Fähigkeit zur deduktiven Argumentation und zur Problemlösung herausfordert. Der Test, genannt "Das Mysterium der sieben Artefakte", umfasst sieben Artefakte, sieben Felder der Magie und sieben Vertraute. Ziel ist es, mithilfe einer Reihe von Hinweisen die korrekten Zuordnungen zwischen diesen Elementen herzustellen und in einer 7x4 Matrix zu positionieren.
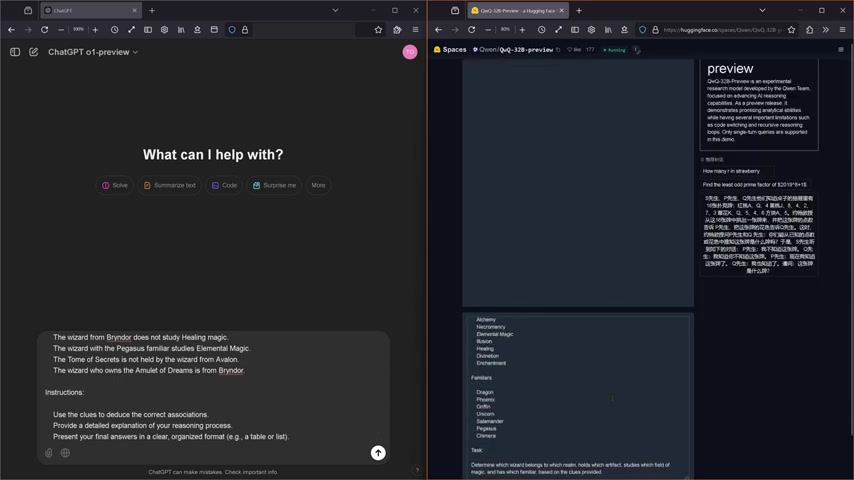
Der Test ist bewusst komplex gestaltet, um die Grenzen der KI-Systeme auszutesten. Ein wirklich fortgeschrittenes System sollte nicht nur in der Lage sein, die richtigen Antworten zu finden, sondern auch seine Denkprozesse transparent darzulegen.
OpenAI o1-Preview: Ein etabliertes KI-System
OpenAI o1-Preview ist ein bekanntes und weit verbreitetes KI-System, das für seine Vielseitigkeit und Leistungsfähigkeit bekannt ist. Es wird in einer Vielzahl von Anwendungen eingesetzt, von der Textgenerierung bis hin zur Code-Erstellung und zur Beantwortung komplexer Fragen. OpenAI o1-Preview dient oft als Referenzpunkt, um die Fähigkeiten neuerer Modelle einzuordnen.
Qwen QwQ-32B: Ein vielversprechendes Nachwuchsmodell
Qwen QwQ-32B hingegen ist ein relativ neues Modell, das von dem Qwen-Team entwickelt wurde. Es handelt sich um ein experimentelles Forschungsmodell, das sich auf fortgeschrittene KI-Fähigkeiten konzentriert. QwQ-32B zeichnet sich durch seine Fähigkeit zum Sprachmischen und Code-Switching aus. Das System kann auch mit mathematischen und verschachtelten Anfragen umgehen, während OpenAI primär in Englisch ist. Die Entwickler sehen es als vielversprechendes Werkzeug zur Lösung analytischer Aufgaben, weisen jedoch gleichzeitig auf seine Grenzen hin.
Der Vergleich: Geschwindigkeit, Transparenz und Argumentation
Geschwindigkeit: QwQ-32B übertrifft o1-Preview
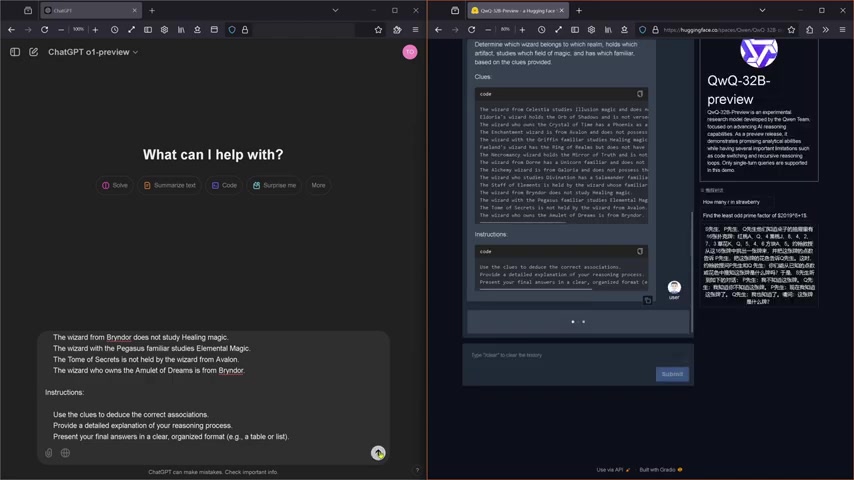
Die erste wichtige Beobachtung ist die Geschwindigkeit, mit der die beiden Systeme den Logiktest bearbeiten. QwQ-32B demonstriert hier eine klare Überlegenheit. Während QwQ-32B den Test in angemessener Zeit abschließt, benötigt OpenAI o1-Preview deutlich länger. In einigen Fällen verstößt es sogar gegen die Nutzungsrichtlinien und muss den Test mit veränderten Parametern wiederholen.
Diese Geschwindigkeitsdifferenz ist ein wesentlicher Vorteil für QwQ-32B, insbesondere in Anwendungen, in denen schnelle Reaktionszeiten entscheidend sind.
Transparenz: QwQ-32B gewährt Einblicke in die Denkprozesse
Ein weiterer wichtiger Aspekt ist die Transparenz der Denkprozesse der KI-Systeme.
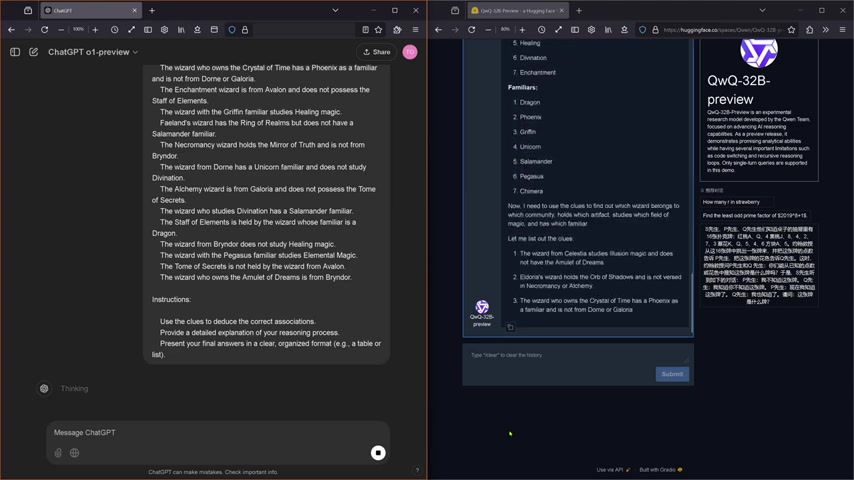
QwQ-32B zeigt während der Bearbeitung des Logiktests seine einzelnen Schritte und Überlegungen. Es gibt dem Benutzer Einblicke in die Art und Weise, wie das System zu seinen Schlussfolgerungen gelangt. OpenAI o1-Preview hingegen hält seine Denkprozesse verborgen.
Diese Transparenz ist aus mehreren Gründen wertvoll. Sie ermöglicht es dem Benutzer, die Logik des Systems besser zu verstehen und zu bewerten. Außerdem kann sie dazu beitragen, Fehler oder Inkonsistenzen in den Schlussfolgerungen des Systems zu erkennen. Dies macht die Fehlersuche im System deutlich einfacher.
Argumentation: Das Aufzeigen der Argumentationskette
Die Art und Weise, wie die KI-Systeme ihre Argumente aufbauen, ist ein weiterer entscheidender Faktor.
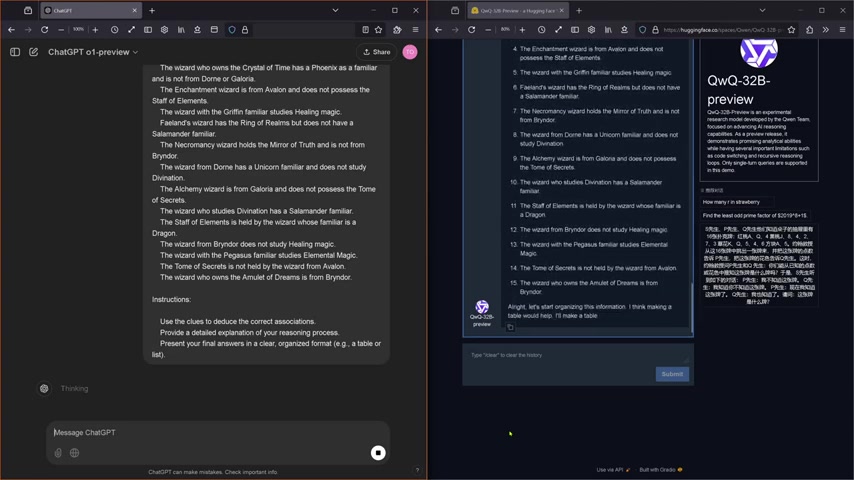
QwQ-32B zeigt eine klare Argumentationskette auf. Das System formuliert Vermutungen, untersucht diese, analysiert Abhängigkeiten und findet am Ende eine oder auch mehr Lösungen, wobei alle Schlussfolgerungen transparent offengelegt werden.
OpenAI o1-Preview hingegen verweigerte bei mehrmaligen Tests diesen Schritt. Es gab lediglich das Endergebnis mit der Begründung, dass das Verhalten gegen die Nutzungsrichtlinien von OpenAI verstößt. Ein Ausschlussgrund, der bis heute nicht reproduziert oder verstanden werden kann.
Most people like

 < 5K
< 5K
 0
0
 < 5K
0
8.7K
0
< 5K
0
8.7K
0
 137.9K
137.9K
 14.05%
3
14.05%
3
 713.6K
713.6K
 15.23%
3
15.23%
3
- App rating
- 4.9
- AI Tools
- 100k+
- Trusted Users
- 5000+
 WHY YOU SHOULD CHOOSE TOOLIFY
WHY YOU SHOULD CHOOSE TOOLIFY
TOOLIFY is the best ai tool source.
- Die Bedeutung von 14 Nanometern in Prozessoren entschlüsselt!
- AMD 1090 CPU: Ein leistungsstarker Desktop-Prozessor
- Maximieren Sie die Leistung Ihres AMD 1055T Phenom II X6 mit Overclocking!
- AMD: Zen 4-Prozessoren und V-Cash CPUs - Rasant entwickelnde Technologiebranche
- Verantwortungsvoller KI-Einsatz bei Intel: Innovative Anwendungen und Deepfake-Erkennung
- La revolución de la inteligencia artificial y el CEO de NVIDIA: Perspectivas del futuro
- ¡Potente procesador de juegos! i3 3220 - Rendimiento, precio y recomendaciones
- AMD vs Nvidia: Welche Grafikkarte ist die beste Wahl für Gaming?
- AMD PBO2 vs. CTR: Die ideale Curve-Optimierer-Anzahl pro Kern finden
- Die Zukunft der Deep Fake-Erkennung: Intel Fake Catcher



