























AI動画文字起こしツール徹底ガイド:WhisperとPythonで効率化
Find AI Tools in second
Find AI Tools No difficulty
No complicated process
Find ai tools
No difficulty
No complicated process
Find ai tools


Table of Contents
AI動画文字起こしツールの概要
動画コンテンツの文字起こしの重要性
近年、動画コンテンツは情報伝達の主要な手段としての地位を確立しています。しかし、動画だけでは情報にアクセスできないユーザーや、視覚情報よりもテキスト情報を好むユーザーも存在します。そこで、動画の文字起こしが重要な役割を果たします。
文字起こしは、動画の内容をテキスト形式に変換するプロセスであり、アクセシビリティの向上、SEO対策、コンテンツの再利用など、多岐にわたるメリットをもたらします。例えば、聴覚障害のあるユーザーは、文字起こしされたテキストを読むことで動画の内容を理解できます。また、検索エンジンは動画の内容を直接クロールできませんが、文字起こしテキストをクロールすることで、動画コンテンツを検索結果に表示させることができます。
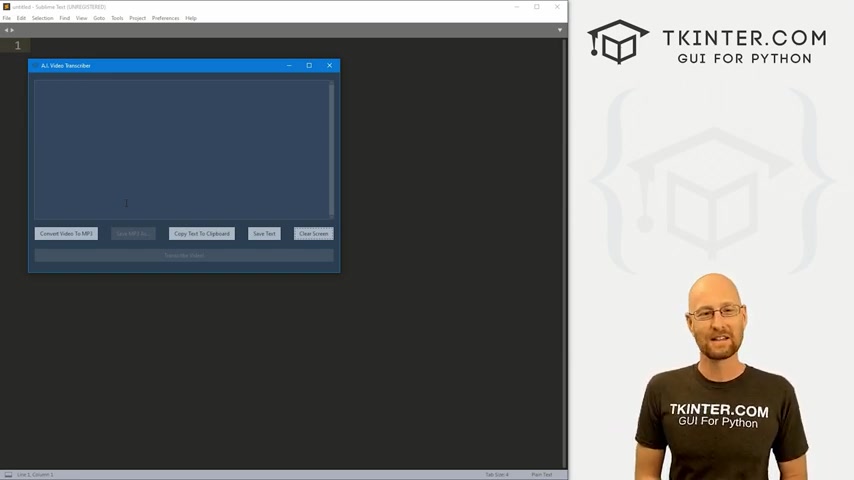
さらに、文字起こしテキストは、ブログ記事、ソーシャルメディアの投稿、プレゼンテーション資料など、様々な形式で再利用できます。これにより、一つの動画コンテンツから複数のコンテンツを生成し、マーケティング効果を最大化することが可能です。
このように、動画の文字起こしは、単なるテキスト変換以上の価値を持ち、動画コンテンツ戦略において不可欠な要素となっています。
AIによる文字起こしのメリット
従来の文字起こしは、人間が手作業で行う必要があり、時間とコストがかかる作業でした。しかし、AI技術の進歩により、高精度な文字起こしを自動で行えるようになりました。
AIによる文字起こしの主なメリットは以下の通りです。
- コスト削減: 人件費を大幅に削減し、予算を他の重要な業務に振り向けることができます。
- 時間短縮: リアルタイムに近いスピードで文字起こしが可能になり、迅速なコンテンツ公開を実現します。
- 高精度: 最新のAIモデルは、専門用語や多様なアクセントにも対応し、高い精度で文字起こしを行います。
- スケーラビリティ: 大量の動画コンテンツにも対応でき、ビジネスの成長に合わせて柔軟に拡張できます。
特に、OpenAIのWhisperモデルは、その優れた性能から注目を集めています。Whisperは、様々な言語に対応し、ノイズの多い環境でも高精度な文字起こしを実現します。Pythonと組み合わせることで、誰でも簡単にAI動画文字起こしツールを構築できます。
AIを活用することで、動画コンテンツの可能性を最大限に引き出し、より多くのユーザーにリーチできるようになります。
PythonとWhisperモデルを選ぶ理由
数あるプログラミング言語とAIモデルの中で、なぜPythonとWhisperモデルを選ぶべきなのでしょうか。
Pythonは、記述の容易さと豊富なライブラリにより、初心者から上級者まで幅広い層に支持されているプログラミング言語です。データ分析、機械学習、Web開発など、様々な分野で活用されており、AI開発に必要なライブラリも豊富に揃っています。例えば、動画ファイルの操作にはmoviepy、GUIアプリケーションの構築にはTkinterやTTK Bootstrapなどが利用できます。
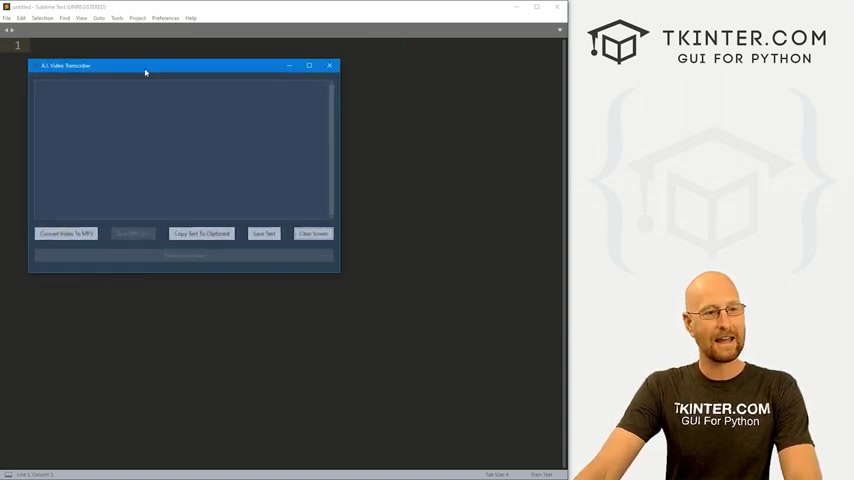
一方、Whisperモデルは、OpenAIが開発した最先端の音声認識モデルです。その最大の特徴は、高い認識精度と多言語対応です。様々な言語の音声データを学習しているため、多様なアクセントや専門用語にも対応できます。また、ノイズキャンセリング機能も搭載されており、騒がしい環境でもクリアな文字起こしが可能です。
PythonとWhisperモデルを組み合わせることで、高度なAI動画文字起こしツールを比較的簡単に構築できます。Pythonの柔軟性とWhisperモデルの高性能が、動画コンテンツ戦略を強力にサポートします。
AI動画文字起こしツール構築の詳細
GUIアプリケーションの作成:TTK BootstrapとTkinter
使いやすいAI動画文字起こしツールを構築するには、直感的なGUI(グラフィカルユーザーインターフェース)が不可欠です。ここでは、Pythonの標準GUIライブラリであるTkinterと、よりモダンなUIを提供するTTK Bootstrapを用いて、GUIアプリケーションを作成する方法を解説します。
Tkinterは、Pythonに標準で付属しているため、追加のインストール作業は不要です。シンプルなUIを作成するのに適していますが、デザインの自由度が低いという欠点があります。一方、TTK Bootstrapは、BootstrapのテーマをTkinterに適用することで、より洗練されたUIを簡単に実現できます。現代的なデザインを取り入れたい場合は、TTK Bootstrapの利用をおすすめします。
GUIアプリケーションの基本的な構成要素は以下の通りです。
- ウィンドウ: アプリケーションのメインウィンドウを作成します。
- ウィジェット: ボタン、テキストボックス、ラベルなど、UIを構成する部品を配置します。
- イベントハンドラ: ボタンのクリックなど、ユーザーの操作に応じて実行される処理を定義します。
これらの要素を組み合わせることで、動画ファイルの選択、文字起こし処理の実行、テキストの表示など、必要な機能を備えたGUIアプリケーションを構築できます。
具体的な手順の例
- TkinterとTTK Bootstrapをインポートする
- メインウィンドウを作成する
- ウィジェット(ボタン、テキストボックスなど)を配置する
- イベントハンドラ(ボタンがクリックされたときの処理など)を定義する
- メインループを開始し、アプリケーションを実行する
これらの手順を参考に、独自のGUIアプリケーションを作成してみてください。
動画からMP3への変換:moviepyの活用
OpenAI APIを利用する際、動画ファイルを直接アップロードすることはできません。そのため、動画ファイルをMP3形式の音声ファイルに変換する必要があります。ここでは、Pythonの動画編集ライブラリであるmoviepyを用いて、動画ファイルをMP3に変換する方法を解説します。
moviepyは、動画のカット、結合、エフェクトの追加など、様々な動画編集機能を備えた強力なライブラリです。シンプルなAPIを提供しており、初心者でも簡単に動画ファイルを操作できます。
動画ファイルをMP3に変換する手順
- moviepyをインストールする
- 動画ファイルを読み込む
- 音声データを取り出す
- MP3ファイルとして保存する
from moviepy.editor import *
# 動画ファイルを読み込む
video = VideoFileClip("your_video.mp4")
# 音声データを取り出す
audio = video.audio
# MP3ファイルとして保存する
audio.write_audiofile("your_audio.mp3")上記のコードを実行することで、動画ファイルをMP3形式に変換できます。変換されたMP3ファイルは、OpenAI APIへのアップロードに使用できます。
ファイルサイズ制限への対応
OpenAI APIには、ファイルサイズ制限(25MB)があります。そのため、動画の長さによっては、MP3ファイルが制限を超える場合があります。その場合は、以下の対策を検討してください。
- 動画の不要な部分をカットする
- MP3ファイルのビットレートを下げる
- 複数のMP3ファイルに分割する
これらの対策を講じることで、ファイルサイズ制限に対応し、OpenAI APIをスムーズに利用できます。
OpenAI APIとの連携:Whisperモデルによる文字起こし
動画ファイルをMP3に変換したら、いよいよOpenAI APIを使って文字起こしを行います。ここでは、Whisperモデルを利用して文字起こしを行う方法を詳しく解説します。
OpenAI APIは、様々なAIモデルへのアクセスを提供するプラットフォームです。Whisperモデルを利用するには、OpenAI APIキーを取得し、PythonのOpenAIライブラリをインストールする必要があります。
文字起こしを行う手順
- OpenAI APIキーを取得する
- OpenAIライブラリをインストールする
- MP3ファイルをOpenAI APIにアップロードする
- Whisperモデルで文字起こしを実行する
- 文字起こし結果を取得する
import openai
# OpenAI APIキーを設定する
openai.api_key = "YOUR_API_KEY"
# MP3ファイルを読み込む
audio_file= open("your_audio.mp3", "rb")
# Whisperモデルで文字起こしを実行する
transcript = openai.Audio.transcribe(
model="whisper-1",
file=audio_file
)
# 文字起こし結果を表示する
print(transcript["text"])上記のコードを実行することで、MP3ファイルの文字起こしを実行できます。文字起こし結果は、テキスト形式で取得できますので、GUIアプリケーションに表示したり、ファイルに保存したりできます。
Whisperモデルの選択
Whisperモデルには、いくつかの種類があります。モデルの種類によって、精度、処理速度、コストが異なります。最適なモデルを選ぶには、以下の要素を考慮してください。
- 言語: 日本語の精度が高いモデルを選択する
- ノイズ: ノイズが多い場合は、ノイズキャンセリング機能が強化されたモデルを選択する
- 予算: コストを抑えたい場合は、精度は多少劣るが、安価なモデルを選択する
これらの要素を考慮し、最適なWhisperモデルを選択してください。
文字起こしテキストの活用方法
AI動画文字起こしツールで生成されたテキストは、様々な用途に活用できます。ここでは、その具体的な活用方法を紹介します。
-
動画への字幕追加: 文字起こしテキストを字幕ファイル(.srtなど)として保存し、動画編集ソフトで動画に追加することで、アクセシビリティを向上させることができます。
-
ブログ記事の作成: 文字起こしテキストをブログ記事のベースとして活用することで、効率的にコンテンツを作成できます。動画の内容をテキストで補足することで、SEO効果も期待できます。
-
ソーシャルメディアへの投稿: 文字起こしテキストから引用を作成し、ソーシャルメディアに投稿することで、動画への誘導を促し、エンゲージメントを高めることができます。
-
議事録の作成: 会議やプレゼンテーションの動画を文字起こしすることで、議事録を簡単に作成できます。重要なポイントをテキストで確認できるため、情報共有や意思決定に役立ちます。
これらの活用方法を参考に、AI動画文字起こしツールで生成されたテキストを最大限に活用してください。
Most people like

 5.1K
5.1K
 35.62%
35.62%
 1
1
 < 5K
1
< 5K
1
 < 5K
2
< 5K
2
 < 5K
1
< 5K
1
 < 5K
3
< 5K
3
- App rating
- 4.9
- AI Tools
- 100k+
- Trusted Users
- 5000+
 WHY YOU SHOULD CHOOSE TOOLIFY
WHY YOU SHOULD CHOOSE TOOLIFY
TOOLIFY is the best ai tool source.
- TSMCが25億ドルを5ナノメートルチップ技術の開発に投資し、Appleとの独占契約を維持する
- GeForce nowでCall of Dutyが登場!今週の新作ゲームと12月の予定も
- あなたのグラフィックカードのパワーを最大限に活用しましょう!
- 最高のパフォーマンスを備えたLenovo IdeaPad Slim 3ラップトップのレビュー
- GeForce NOWでSteam DeckでのCall of Duty MW3、MW2&Warzoneをプレイ
- AMD Radeon ソフトウェア:パフォーマンス向上のための最新ドライバー
- デジタル変革の重要性と成功のポイント
- 危機的な脅威からアメリカを守る追跡戦
- 2021年冷却ファン比較評価!AMD Ryzen 9 5950Xに最適なクーラー
- H100とH800の比較分析:AIチップ輸出規制下の最適戦略



