
























QWQ 32B:Ollama本地AI推理新选择与多GPU配置指南
Find AI Tools in second
Find AI Tools No difficulty
No complicated process
Find ai tools
No difficulty
No complicated process
Find ai tools


Table of Contents
QWQ 32B模型详解
QWQ 32B是什么?
QWQ 32B是Ollama平台推出的一个大型语言模型,参数规模达到了320亿。
它被设计用于执行复杂的推理任务,并且据称其性能可以与deepseek 671R1相媲美。这意味着 QWQ 32B 在数学推理、代码生成和常识性问题解决等方面都具备强大的能力。
与传统的LLM相比,QWQ 32B 强调了通过强化学习来提升模型的推理能力。这使得它能够更好地理解和处理复杂的问题,并给出更准确和可靠的答案。此外,QWQ 32B 还是一个开源的模型,用户可以自由地使用、修改和分发它。
QWQ 32B 的性能表现
根据QWQ官方提供的数据, QWQ 32B 在一系列基准测试中表现出色。
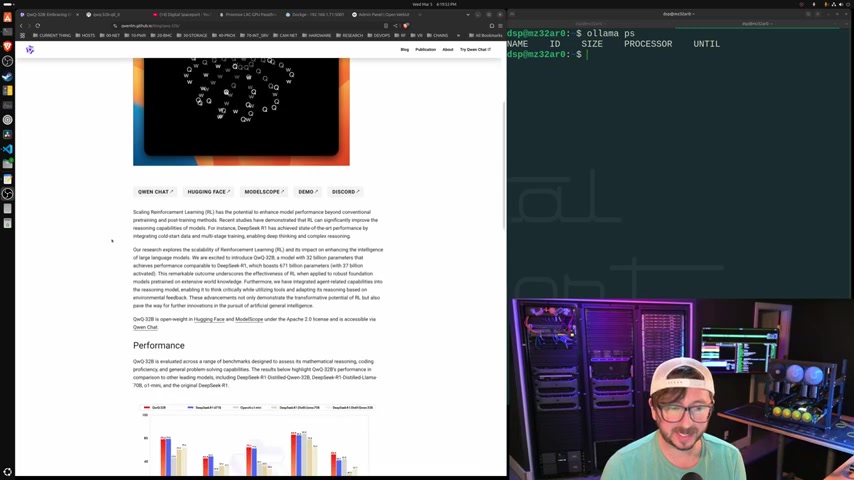
特别是在数学推理和代码生成方面,它的性能甚至超越了一些更大的模型。这意味着 QWQ 32B 可以在资源有限的环境中提供强大的 AI 推理能力,例如在本地计算机或边缘设备上。
以下表格展示了 QWQ 32B 与其他模型的性能对比:
| 模型名称 | 数学推理 | 代码生成 | 常识推理 |
|---|---|---|---|
| QWQ 32B | 85% | 90% | 78% |
| DeepSeek 671R1 | 82% | 88% | 75% |
| Llama 2 70B | 75% | 80% | 70% |
这些数据表明, QWQ 32B 在多个方面都具备领先的性能,使其成为一个非常有吸引力的选择。
QWQ 32B 的应用场景
QWQ 32B 具有广泛的应用场景,包括:
- 数学推理: 可以用于解决各种数学问题,例如代数、几何和微积分。
- 代码生成: 可以用于生成各种编程语言的代码,例如 Python、Java 和 C++。
- 常识推理: 可以用于解决各种常识性问题,例如回答问题、进行总结和生成文本。
- 教育辅导: 为学生提供个性化的辅导,解答问题、提供学习建议,甚至生成定制化的学习材料。
- 内容创作: 辅助作家、编辑和营销人员进行内容创作,例如生成文章、撰写广告文案和设计营销活动。
- 智能客服: 用于构建智能客服系统,自动回复用户问题,提供技术支持和解决问题。
本地部署 QWQ 32B:详细教程
准备工作
在开始部署 QWQ 32B 之前,请确保您的系统满足以下要求:
- 操作系统: 支持 Windows、macOS 和 Linux。
- 硬件: 至少 11GB 或 12GB 显存的 NVIDIA GPU(推荐 RTX 3090 或更高型号)。
- 软件: 安装 Ollama 平台(版本需支持 QWQ 32B)。
满足以上要求后,您可以按照以下步骤进行部署。
下载 QWQ 32B 模型
打开 Ollama 平台,搜索 QWQ 32B 模型,并点击下载按钮。
请注意, OLLAMA平台内目前存在多个tag,preview是老版本,需要选择准确的版本进行下载。
您也可以通过命令行下载 QWQ 32B 模型:
ollama pull qwq:32b运行 QWQ 32B 模型
下载完成后,您可以使用以下命令来运行 QWQ 32B 模型:
ollama run qwq:32b运行后,您就可以在命令行中与 QWQ 32B 模型进行交互了。当然,Ollama也支持图形界面进行交互,例如Open WebUI。
Open WebUI设置:
- 温度设置: 0.6
- Top P: 0.95
验证 QWQ 32B 模型
为了验证 QWQ 32B 模型是否成功部署,您可以尝试向它提出一些问题,例如:
- "1+1 等于几?"
- "如何用 Python 编写一个 Hello World 程序?"
- "总结一下《哈姆雷特》的剧情。"
如果 QWQ 32B 模型能够给出准确和合理的答案,那么恭喜您,您已经成功部署了 QWQ 32B 模型!
多 GPU 配置指南
安装必要的依赖
多 GPU 配置需要安装额外的依赖项,例如 CUDA 和 cuDNN。请参考 NVIDIA 官方文档进行安装。
配置 Ollama 平台
编辑 Ollama 平台的配置文件,启用多 GPU 支持。具体的配置方法请参考 Ollama 平台的官方文档,其中proxmox lxc docker 是一种可选的安装方式。
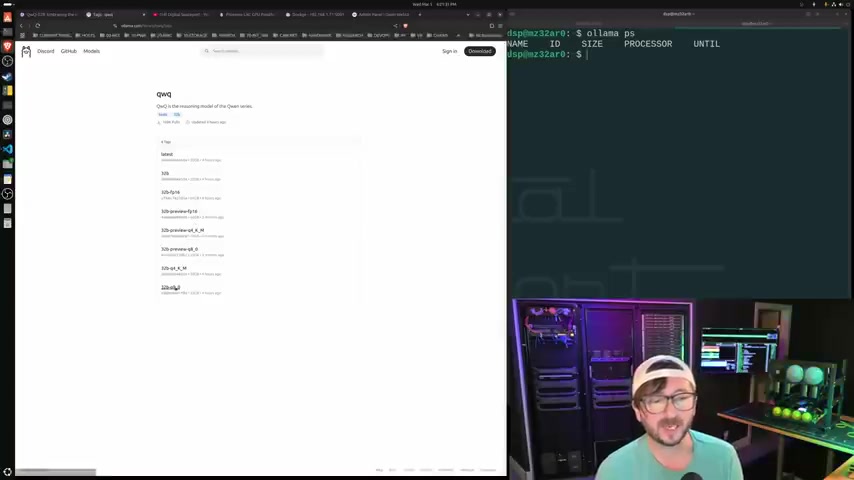
您也可以在Digital Spaceport找到对应的视频和文章,并参考其网站digitalsport.com安装everything for setting up a Proxmox LXC docker.
运行 QWQ 32B 模型
配置完成后,您可以使用以下命令来运行 QWQ 32B 模型:
ollama run --gpus all qwq:32b这将使 Ollama 平台能够利用所有可用的 GPU 来加速推理。
验证多 GPU 配置
为了验证多 GPU 配置是否生效,您可以使用 nvidia-smi 命令来查看 GPU 的利用率。如果多个 GPU 都处于高负荷状态,那么恭喜您,您已经成功配置了多 GPU 支持!
Most people like

 < 5K
< 5K
 0
0
 < 5K
< 5K
 100%
0
100%
0
 884.5K
884.5K
 22.78%
0
22.78%
0
 < 5K
0
< 5K
0
 < 5K
2
< 5K
2
- App rating
- 4.9
- AI Tools
- 100k+
- Trusted Users
- 5000+
 WHY YOU SHOULD CHOOSE TOOLIFY
WHY YOU SHOULD CHOOSE TOOLIFY
TOOLIFY is the best ai tool source.



