8 Einfache Möglichkeiten, RCA Audio in AUX umzuwandeln
Bestes rca audio to aux im Jahr 2025
Open-Source-Audiomodell für kurze Audio-Proben
Stable Audio Open ist ein Open-Source-Modell, das optimiert ist, um kurze Audio-Proben, Soundeffekte und Produktions-Elemente mithilfe von Texteingaben zu generieren. Es ermöglicht Benutzern, bis zu 47 Sekunden hochwertige Audio-Daten aus einfachen Texteingaben zu erstellen.
Um Stable Audio Open zu verwenden, laden Sie das Modell von Hugging Face herunter, installieren Sie Abhängigkeiten, laden Sie das Modell, generieren Sie Audio basierend auf Texteingaben und speichern Sie das Ergebnis im WAV-Format.
Open Source Model
Spezielle Schulung
Anpassbar
Fokussiert auf kurze Audio-Clips
stable audio open bietet Ihnen AI-Musikgenerator,Aufnahme,KI-Audioverstärker Text-zu-Audio-Modell,Kurze Audio-Proben,Soundeffekt-Generierung,Kostenloses Audio-Modell,Musikproduktionswerkzeug, die Sie für all diese KI-Funktionen verwenden können.
Zusammenfassung: Jenseits von Worten bietet eine Plattform zur Umwandlung von Text in Audio mit KI-Stimmen und einem CMS.
Jenseits von Worten ist eine Plattform, die es Benutzern ermöglicht, Text in ansprechenden Audio umzuwandeln. Sie bietet ein All-in-One-Audio-Content-Management-System (CMS) und KI-Stimmen, um Publishing-Workflows zu verbessern.
Um Jenseits von Worten zu nutzen, können Benutzer einfach ihren Text in die Plattform eingeben und aus einer Auswahl an KI-Stimmen auswählen. Der Text wird dann in hochwertiges Audio umgewandelt. Benutzer können auch ihren Audio-Inhalt über das integrierte CMS verwalten.
Die Kernfunktionen von Jenseits von Worten umfassen Text-to-Speech-Umwandlung, KI-Stimmen, Audio-Content-Management-System (CMS) und nahtlose Integration in Publishing-Workflows.
SpeechKit bietet Ihnen Text-zu-Sprache,AI Sprachsynthese,KI-Audioverstärker Text-to-Speech,Audio-Publishing,KI-Stimmen,CMS, die Sie für all diese KI-Funktionen verwenden können.
Konvertieren Sie Audio mühelos in Notizen.
OneAudio ist eine Plattform, die es Benutzern ermöglicht, Audioaufzeichnungen zusammenzufassen, zu transkribieren und in saubere und gut strukturierte Notizen umzuwandeln.
Um OneAudio zu verwenden, denken Sie einfach laut oder laden Sie eine Audioaufzeichnung hoch. Die Plattform unterstützt Sie dann bei der Erstellung einer fertigen, teilenbereiten Notiz.
Sprache zu Text
Transkript
Audio zu Text
Einfache Notizen
Zusammenfassungen
KI
OneAudio AI bietet Ihnen KI-Audioverstärker,AI-Produktbeschreibungs-Generator,AI-Spracherkennung,AI Notizassistent,Aufnahme,Sprache-zu-Text,Transkription,Transkribierer zusammenfassen,transkribieren,audio zu text,notizen machen,KI, die Sie für all diese KI-Funktionen verwenden können.
Verbessern Sie die Audioqualität mit KI.
Audio Enhancer ist ein KI-gestütztes Tool, das darauf ausgelegt ist, die Audioqualität zu verbessern, indem Hintergrundgeräusche entfernt werden. Es bietet eine einfache und effiziente Lösung zur Verbesserung der Klarheit und Gesamtqualität von Audioaufnahmen.
Um Audio Enhancer zu verwenden, laden Sie einfach Ihre Audiodatei hoch, wählen Sie die Verbesserungsoptionen wie Rauschreduzierung aus und laden Sie die verbesserte Datei herunter.
KI-gestützte Audioverbesserung
Hintergrundgeräuschentfernung
Datei-Upload bis zu 500MB
Unterstützt verschiedene Dateiformate
Audio Enhancer bietet Ihnen KI-Audioverstärker,AI-Fotoverbesserer,AI-Bildverbesserer,KI-Podcast-Assistent Audioverbesserung,KI-gestütztes Tool,Hintergrundgeräuschentfernung,Podcast-Verbesserung,Audiosteigerung in Videos,Musikaufnahme-Verbesserung, die Sie für all diese KI-Funktionen verwenden können.

Konvertiere kantonesische Audio in Text
Ein Werkzeug, um kantonesische Audio-Nachrichten in Text umzuwandeln
Registrieren Sie den Rapid API-Token über den bereitgestellten Link
Konvertiere kantonesische Audio in Text
Speech to Text by cantonese.ai bietet Ihnen Transkription,Transkribierer,Sprache-zu-Text,Untertitel oder Untertitel Audio zu Text,Produktivität,Kantonesisch,Rapid API, die Sie für all diese KI-Funktionen verwenden können.
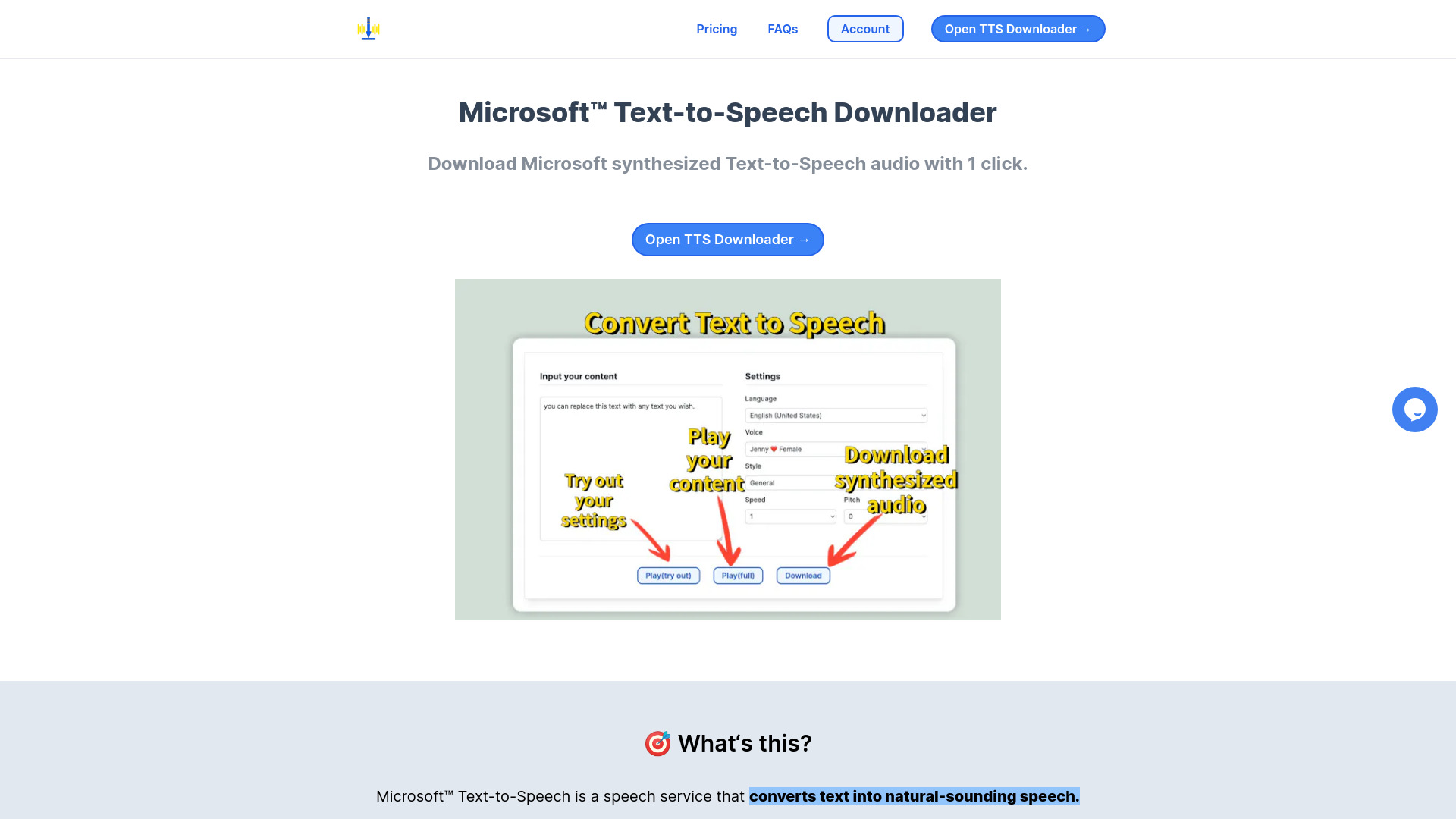
Text-to-Speech-Audio-Synthese mit 1 Klick
Microsoft Text-to-Speech Downloader ist ein Dienst, der es Benutzern ermöglicht, Audios aus Text mithilfe von Microsoft™ Text-to-Speech zu synthetisieren. Es bietet eine einfache Möglichkeit, Text in natürlich klingende Sprache umzuwandeln und dann das Audio mit nur einem Klick abzuspielen oder herunterzuladen.
Um den Microsoft Text-to-Speech Downloader zu verwenden, geben Sie einfach Ihren Text ein, wählen Sie die gewünschten Stimmen- und Spracheinstellungen aus und klicken Sie dann auf die Schaltfläche 'Download', um sofort die Audioausgabe zu generieren.
Text in natürlich klingende Sprache umwandeln
Audio mit 1 Klick herunterladen
MS Text-to-Speech Downloader bietet Ihnen Text-zu-Sprache,AI Sprachsynthese Text-to-Speech-Konverter,Sprachsynthese-Tool,Audio-Downloader,Natürlich klingende Sprache, die Sie für all diese KI-Funktionen verwenden können.
Unbegrenzte Transkription von Audio und Video zu Text
Die Website für Kostenlose unbegrenzte Audio-, Video-zu-Text-Transkription ist ein leistungsstarkes Werkzeug, das es Benutzern ermöglicht, Audio- und Videodateien ohne Einschränkungen in Text umzuwandeln. Sie bietet eine nahtlose und effiziente Möglichkeit, Inhalte genau und schnell zu transkribieren.
Die Verwendung der Website für Kostenlose unbegrenzte Audio-, Video-zu-Text-Transkription ist einfach. Laden Sie einfach Ihre Audio- oder Videodatei hoch, und die Plattform transkribiert den Inhalt in Text mit unbegrenzter Nutzung.
Unbegrenzte Audio-zu-Text-Transkription
Unbegrenzte Video-zu-Text-Transkription
ScribeBuddy Transcribe Audio, Video to Text for free bietet Ihnen KI-Podcast-Assistent Audio-Transkription,Video-Transkription,Textumwandlung,Uneingeschränkte Nutzung, die Sie für all diese KI-Funktionen verwenden können.
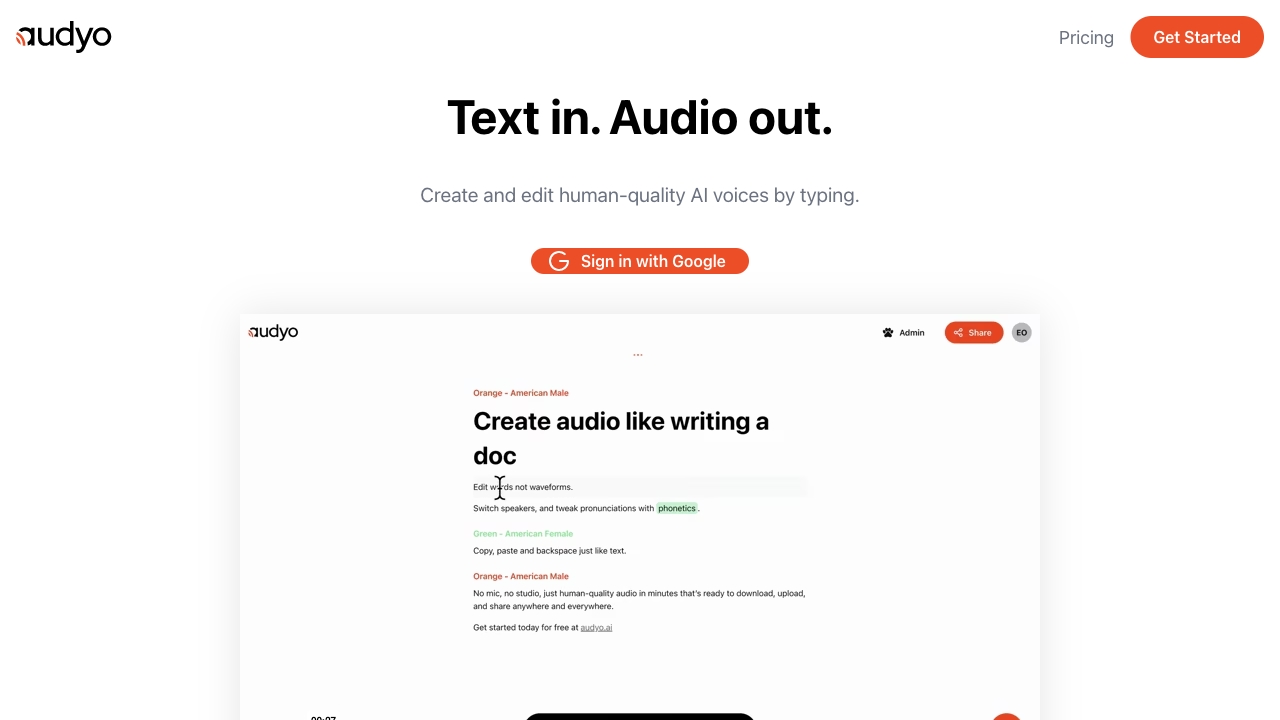
Audyo ist eine Plattform, die es Benutzern ermöglicht, Audio zu bearbeiten und zu erstellen, ähnlich wie das Schreiben eines Dokuments.
Audyo ist eine Plattform, die es Benutzern ermöglicht, Audio zu erstellen, ähnlich wie das Schreiben eines Dokuments. Es bietet die Möglichkeit, Wörter anstatt von Wellenformen zu bearbeiten, zwischen Sprechern zu wechseln und Aussprachen mithilfe von Phonetik anzupassen.
Um Audyo zu nutzen, melden Sie sich einfach mit Ihrem Google-Konto an und beginnen Sie mit dem Tippen. Die Plattform wandelt Ihren Text in qualitativ hochwertige AI-Stimmen um. Sie können den Text bearbeiten, zwischen Sprechern wechseln und Aussprachen anpassen, um den gewünschten Audio-Output zu erstellen.
Wörter anstatt von Wellenformen bearbeiten
Zwischen Sprechern wechseln
Aussprachen mit Phonetik anpassen
Ihr Publikum mit qualitativ hochwertigen AI-Stimmen begeistern
Einfach zu bedienen, genau wie das Tippen
Audyo bietet Ihnen KI-Audioverstärker,AI-Inhaltegenerator,AI-Spracherkennung,AI Sprachsynthese,Text-zu-Sprache Audioproduktion,AI-Stimmen,Text-to-Speech,Stimmindividualisierung,Phonetik,Sprecherwechsel,Wellenformbearbeitung, die Sie für all diese KI-Funktionen verwenden können.
Abschließende Worte
Der Artikel behandelt verschiedene Open-Source-Audio-Modelle und Plattformen, die KI-Technologie nutzen, um Audio-Inhalte zu generieren, zu verbessern und zu transkribieren. Stable Audio Open ist ein Open-Source-Modell, das sich auf die Generierung von kurzen Audio-Proben und Soundeffekten aus Textvorgaben spezialisiert hat. BeyondWords ist eine Plattform, die Text in ansprechende Audio-Dateien mit KI-Stimmen und einem CMS umwandelt. OneAudio ermöglicht es Benutzern, Audio-Aufnahmen zusammenzufassen und zu transkribieren, um gut strukturierte Notizen zu erstellen. Der Audio-Enhancer ist ein KI-gestütztes Werkzeug, das die Audioqualität verbessert, indem Hintergrundgeräusche entfernt werden. SpeechKit bietet Text-zu-Sprache-Konvertierung und KI-Stimmen für Veröffentlichungsworkflows. Der Artikel erwähnt auch Tools zur Umwandlung von kantonesischem Audio in Text, zur Synthese von Text zu Sprache mit dem Microsoft Text-to-Speech-Downloader und zur Transkription von Audio- und Videoinhalten mit unbegrenzter Nutzung. Audyo ist eine Plattform, die es Benutzern ermöglicht, Audio-Inhalte mühelos zu bearbeiten und zu erstellen. Diese KI-Funktionen sollen die Audio-Produktion, Transkription und Inhalteerstellung für ein nahtloses Benutzererlebnis verbessern.
Über den Autor

I'm a Guest Author specializing in AI and visual content. I combine analytical insights with engaging imagery to bring the AI narrative to life, offering readers a clear, vivid understanding of how this technology shapes our visual world.
Mehr KI-Tools
- 8 Creative Ways to Use AI Image Generators in Your Projects
- 15 Mind-Blowing AI Art Generators You Need to Try
- 7 Incredible Ways AI Generators Are Revolutionizing Content Creation
- 13 Powerful Software Voice-to-Text Tools to Boost Productivity
- 15 Tricks to Convert Audio to Sheet Music Like a Pro
- 13 Tips to Transcribe MP3 Audio Files to Text Easily
Hervorgehoben*

 19.75%
19.75% 44.20%
44.20% 22.31% 48.05%
22.31% 48.05% 100.00% 30.37%
100.00% 30.37% 20.96% 46.33% 57.83% 6.67%
20.96% 46.33% 57.83% 6.67%