15 Lợi Ích Bất Ngờ của Dữ Liệu Tổng Hợp trong Phát Triển Trí Tuệ Nhân Tạo
Synthetic Data tốt nhất trong 2025

Tạo dữ liệu đào tạo được gắn nhãn cho trí tuệ nhân tạo về trực quan.
Dữ liệu tổng hợp cho trực quan và trí tuệ nhân tạo. Tạo dữ liệu đào tạo được gắn nhãn theo yêu cầu cho mô hình đạo đức, chính xác và hiệu quả.
Đăng ký một tài khoản, chọn bộ dữ liệu mong muốn và truy cập vào dữ liệu tổng hợp để đào tạo trí tuệ nhân tạo về trực quan.
Dữ liệu đào tạo được gắn nhãn theo yêu cầu
Nền tảng tạo dữ liệu có khả năng mở rộng cao
Hình ảnh và video chân thực
Mô hình con người 3D đa dạng
Bộ nhãn hoàn hảo từng pixel
synthesis.ai cung cấp cho bạn Trình tạo ảnh và hình ảnh của AI,Nhận diện hình ảnh bằng trí tuệ nhân tạo dữ liệu tổng hợp,trực quan,trí tuệ nhân tạo,dữ liệu đào tạo được gắn nhãn,tạo dữ liệu,hình ảnh chân thực,mô hình con người 3D,nhãn hoàn hảo từng pixel,xác minh danh tính,giám sát tài xế,thử đồ ảo,hội nghị truyền hình,bảo mật mà bạn có thể sử dụng cho tất cả các tính năng trí tuệ nhân tạo này.
syntheticAIdata tạo ra dữ liệu tổng hợp chất lượng cao để huấn luyện các mô hình AI thị giác, được hỗ trợ bởi Microsoft và NVIDIA.
syntheticAIdata là một nền tảng giúp doanh nghiệp tạo ra dữ liệu tổng hợp chất lượng cao để huấn luyện các mô hình AI thị giác. Nó cung cấp một giải pháp tiết kiệm chi phí để thu thập dữ liệu tổng hợp và cung cấp hỗ trợ cho các nhiệm vụ thị giác máy tính khác nhau như phân loại hình ảnh, phân đoạn và phát hiện đối tượng. Platform được hỗ trợ bởi Microsoft for Startups và là một phần của chương trình NVIDIA Inception.
Để sử dụng syntheticAIdata, làm theo các bước sau: 1. Tải lên 3D model của bạn bằng bảng điều khiển dựa trên web. 2. Cấu hình các tùy chọn cho việc tạo dữ liệu, chẳng hạn như nền và ánh sáng hoặc sử dụng các tùy chọn mặc định. 3. Tải xuống dữ liệu tổng hợp được tạo ra, có thể lưu trữ trong tài khoản của bạn để sử dụng sau này. 4. Tích hợp giải pháp với các dịch vụ dựa trên đám mây hoặc nhập dữ liệu vào môi trường phát triển của bạn để huấn luyện các mô hình AI.
Các tính năng chính của syntheticAIdata bao gồm: - 3D Models: Nhập các mô hình 3D thực tế để tạo dữ liệu tổng hợp cho việc huấn luyện mô hình AI thị giác. - Backgrounds: Lựa chọn từ nhiều màu sắc và hình dạng, hình ảnh thế giới thực và nền tự động tạo. - Lighting: Tùy chỉnh các tùy chọn ánh sáng để tăng tính thực tế của các mô hình 3D và đa dạng hóa dữ liệu tổng hợp. - Annotation Types: Hỗ trợ ba loại chú thích hình ảnh phổ biến - phát hiện đối tượng, phân đoạn ngữ nghĩa và phân loại hình ảnh. - Scaling: Dễ dàng mở rộng việc tạo dữ liệu để tạo ra nhóm hình ảnh phù hợp với yêu cầu của bạn và cải thiện độ chính xác của mô hình.
SyntheticAIdata cung cấp cho bạn Trình tạo ảnh và hình ảnh của AI,Trình tạo mô hình 3D AI dữ liệu tổng hợp,tạo dữ liệu tổng hợp,giải pháp dữ liệu tổng hợp,dịch vụ dữ liệu tổng hợp saas,thị giác máy tính,trí tuệ nhân tạo,học máy,AI,ML mà bạn có thể sử dụng cho tất cả các tính năng trí tuệ nhân tạo này.
Incribo cung cấp dữ liệu tổng hợp chất lượng cao với giá cả phải chăng, mô phỏng dữ liệu thực mà không ảnh hưởng đến quyền riêng tư.
Incribo là một nền tảng cung cấp dữ liệu tổng hợp chất lượng cao với giá cả phải chăng. Dữ liệu tổng hợp, trong ngữ cảnh này, thể hiện dữ liệu được tạo ra nhân tạo mô phỏng các đặc điểm của dữ liệu thực trong khi bảo vệ thông tin nhạy cảm.
Để sử dụng Incribo, bạn có thể đăng ký tài khoản trên trang web và truy cập các tính năng tạo dữ liệu. Bạn có thể chỉ định định dạng, cấu trúc và kích thước của bộ dữ liệu tổng hợp bạn cần. Các thuật toán và mô hình tiên tiến của Incribo sẽ tạo ra dữ liệu tổng hợp dựa trên yêu cầu của bạn.
Các tính năng chính của Incribo bao gồm: 1. Tạo dữ liệu tổng hợp chất lượng cao 2. Giá cả phải chăng 3. Khả năng chỉ định định dạng, cấu trúc và kích thước của bộ dữ liệu 4. Bảo vệ thông tin nhạy cảm trong khi duy trì các đặc điểm thực tế của dữ liệu
Aurora AI cung cấp cho bạn Khác dữ liệu tổng hợp,chất lượng cao,phải chăng,tạo dữ liệu mà bạn có thể sử dụng cho tất cả các tính năng trí tuệ nhân tạo này.
Một công cụ được gọi là Yadget giúp người tạo dữ liệu tổng hợp để kiểm tra sản phẩm kỹ thuật số.
Yadget là một công cụ tạo dữ liệu được thiết kế để hỗ trợ người tạo ra tạo ra dữ liệu tổng hợp để kiểm tra và xác thực sản phẩm kỹ thuật số của họ. Nó đặc biệt hữu ích cho các dự án ML và AI.
Để sử dụng Yadget, chỉ cần đăng ký một tài khoản trên trang web. Sau khi đăng nhập, bạn có thể truy cập công cụ tạo dữ liệu và chọn các loại dữ liệu mong muốn. Yadget sau đó sẽ tạo ra dữ liệu tổng hợp theo các yêu cầu của bạn. Dữ liệu này có thể được sử dụng để kiểm tra và xác thực sản phẩm kỹ thuật số của bạn hoặc trong các dự án ML và AI.
Công cụ tạo dữ liệu
Tạo dữ liệu tổng hợp
Kiểm tra sản phẩm kỹ thuật số
Hỗ trợ dự án ML và AI
Yadget cung cấp cho bạn Trình tạo nội dung AI,Trình tạo video AI Công cụ tạo dữ liệu,Dữ liệu tổng hợp,Kiểm tra sản phẩm kỹ thuật số,Dự án ML,Dự án AI,Phân tích dữ liệu mà bạn có thể sử dụng cho tất cả các tính năng trí tuệ nhân tạo này.

Crayon Data cung cấp nền tảng maya.ai để cá nhân hóa trí tuệ nhân tạo và tăng doanh thu.
Crayon Data là một công ty trí tuệ nhân tạo và dữ liệu lớn có trụ sở tại Singapore, cung cấp nền tảng maya.ai để giúp các doanh nghiệp tăng doanh thu thông qua việc cá nhận hóa trí tuệ nhân tạo. Nền tảng này giúp các doanh nghiệp mở khóa giá trị của dữ liệu, tăng khả năng tương tác với khách hàng và đẩy mạnh doanh thu.
Để sử dụng nền tảng maya.ai của Crayon Data, các doanh nghiệp có thể làm theo các bước sau đây: 1. Đăng ký tài khoản với Crayon Data. 2. Truy cập nền tảng maya.ai và khám phá cấu trúc mô-đun của nó, bao gồm khả năng liên quan đến dữ liệu, gợi ý và trải nghiệm người dùng. 3. Kết nối các hệ sinh thái liên quan và tận dụng các thuật toán đã được cấp bằng sáng chế để cung cấp các gợi ý cá nhân hóa cho mỗi khách hàng. 4. Sử dụng các API plug and play để tích hợp các mô-đun của nền tảng vào các hệ thống và sản phẩm hiện có. 5. Hưởng lợi từ tính mở rộng, tính bảo mật và tính riêng tư của nền tảng để đảm bảo an toàn dữ liệu. 6. Lựa chọn từ các ngành như ngân hàng tiêu dùng, fintech, du lịch, phân phối công nghệ, và bán lẻ để áp dụng khả năng trí tuệ nhân tạo của nền tảng cho việc tăng doanh thu. 7. Truy cập các giải pháp đã được sử dụng trên nền tảng AI và khám phá các trường hợp sử dụng thực tế để xem cách maya.ai có thể tăng doanh thu. 8. Tham gia vào hệ sinh thái của Crayon Data để hợp tác và thúc đẩy sự đổi mới hơn nữa.
Cấu trúc mô-đun
Các thuật toán đã được cấp bằng sáng chế cho gợi ý cá nhân hóa
Các API plug and play để dễ dàng tích hợp
Tính mở rộng và độc lập với đám mây
Gợi ý thời gian thực dựa trên sở thích người dùng
Biện pháp bảo mật và riêng tư dữ liệu
Maya cung cấp cho bạn Phát triển lãnh đạo AI,Khai thác dữ liệu trí tuệ nhân tạo,Mô hình Ngôn ngữ Lớn (LLMs),Trợ lý Quảng cáo AI Cá nhân hóa trí tuệ nhân tạo,Tăng tốc doanh thu,Dữ liệu lớn,Nền tảng maya.ai,Cấu trúc mô-đun,Gợi ý cá nhân hóa,Thu nhập từ dữ liệu,Tương tác với khách hàng,Giải pháp theo ngành,Phân tích dữ liệu mà bạn có thể sử dụng cho tất cả các tính năng trí tuệ nhân tạo này.

Đơn giản hóa việc phân tích dữ liệu cho các Dự án Web3
Đơn giản hóa việc phân tích dữ liệu và thông tin kinh doanh cho các Dự án Web3
Chúng tôi giúp các doanh nghiệp tận dụng dữ liệu để hiểu rõ hơn về khách hàng, người dùng và người sở hữu. Nền tảng của chúng tôi chuyển dữ liệu trên chuỗi và ngoại chuỗi thành những thông tin hữu ích giúp tăng trưởng của bạn. Được cung cấp bởi trí tuệ nhân tạo và phân tích dữ liệu.
Bảng điều khiển sẵn sàng sử dụng: Tạo bảng đo lường chỉ số bằng một vài cú nhấp chuột cho dự án của bạn. Không cần đội ngũ dữ liệu nội bộ
Kết hợp Dữ liệu: Kết hợp dữ liệu trên chuỗi với dữ liệu ngoại chuỗi như CRM, Nhãn ví, v.v. để khám phá thêm những thông tin tiềm ẩn
Dịch vụ Tùy chỉnh: Dịch vụ phân tích dữ liệu của chúng tôi có thể hỗ trợ bất kỳ yêu cầu đặc biệt nào. Hoặc bạn có thể tự xây dựng bằng truy vấn SQL
Hồ sơ Khách hàng: Phân loại dữ liệu trên chuỗi và ngoại chuỗi để làm giàu hồ sơ khách hàng, giúp bạn tạo ra chiến dịch cá nhân hóa hoặc nhắm mục tiêu các nhóm người dùng có lợi nhuận cao nhất
Phân tích Cơ bản: Hiểu cách khách hàng tìm kiếm, tương tác hoặc mua sản phẩm của bạn qua phân tích Nhóm, Miệng nước & Quá trình
Phân đoạn: Phân loại khách hàng thành các nhóm khác nhau như khách hàng có giá trị nhất, tương tác nhiều nhất, tương tác cao nhất để bạn có thể tối ưu hóa và cải thiện kế hoạch tiếp thị, bán hàng hoặc phát triển
Trợ lý Trí tuệ nhân tạo: Yêu cầu Trí tuệ nhân tạo cập nhật chỉ số quan trọng hoặc dự đoán về các hoạt động tương lai như mua hàng, churn hoặc giao dịch và hành vi bất thường
DeepEyes Analytics cung cấp cho bạn Trợ lý Phân tích AI,Trợ lý Quảng cáo AI,Khai thác dữ liệu trí tuệ nhân tạo,Web3,Biểu đồ AI,Blockchain phan tich du lieu,thong tin kinh doanh,Dự án Web3,dữ liệu trên chuỗi,dữ liệu ngoại chuỗi,Trí tuệ nhân tạo,phân loại khách hàng,phân tích khung,phân đoạn,kết hợp dữ liệu,chỉ số,bảng điều khiển,tiếp thị,bán hàng,phát triển,Phân tích tăng cường,Martech,Theo dõi Tiền thông minh,Theo dõi Kẻ khai thác,Bảng điều khiển chuỗi mới nhất,Theo dõi Đánh giá trên chuỗi mà bạn có thể sử dụng cho tất cả các tính năng trí tuệ nhân tạo này.
Dễ dàng tạo dữ liệu mẫu với MockThis, một công cụ được hỗ trợ bởi trí tuệ nhân tạo (AI) sử dụng GPT để tạo ra dữ liệu tổng hợp có tính thực tế.
MockThis là một công cụ được hỗ trợ bởi trí tuệ nhân tạo (AI) cho phép người dùng dễ dàng tạo ra dữ liệu mẫu. Nó sử dụng GPT (Generative Pre-trained Transformer) để tạo ra dữ liệu tổng hợp có tính thực tế cho nhiều mục đích sử dụng khác nhau.
Để sử dụng MockThis, đơn giản truy cập vào trang web hoặc truy cập API. Nhập số lượng ví dụ mong muốn và xác định định dạng dữ liệu bằng JSON hoặc chọn từ các giao diện có sẵn. Gửi yêu cầu và nhận dữ liệu mẫu tự động được tạo ra dưới dạng JSON.
Tạo dữ liệu mẫu với sức mạnh của trí tuệ nhân tạo (AI)
Tích hợp với GPT, MisterD.dev, Github, Twitter
Hỗ trợ định dạng dữ liệu JSON
Tùy chỉnh giao diện
Tùy chọn tạo ra nhiều ví dụ
MockThis cung cấp cho bạn Danh mục Công cụ AI tạo dữ liệu mẫu tự động,công cụ được hỗ trợ bởi trí tuệ nhân tạo (AI),tích hợp GPT,tạo dữ liệu mẫu,phát triển phần mềm,kiểm thử,tạo nguyên mẫu,thiết kế giao diện người dùng (UI/UX),phân tích dữ liệu,trực quan hóa dữ liệu,học máy,JSON mà bạn có thể sử dụng cho tất cả các tính năng trí tuệ nhân tạo này.
Trang web cộng đồng dành cho các nhà khoa học dữ liệu và người hâm mộ trí tuệ nhân tạo.
Open Data Science là một trang web cộng đồng dành cho các nhà khoa học dữ liệu và những người đam mê trí tuệ nhân tạo.
Để sử dụng Open Data Science, chỉ cần đăng ký tài khoản trên trang web và tham gia các hướng dẫn, cuộc thi và dự án khác nhau.
Diễn đàn cộng đồng
Cuộc thi khoa học dữ liệu
Hướng dẫn học máy
ods.ai cung cấp cho bạn Khóa học AI,Trợ lý Phân tích AI khoa học dữ liệu,trí tuệ nhân tạo,học máy,cộng đồng,cuộc thi mà bạn có thể sử dụng cho tất cả các tính năng trí tuệ nhân tạo này.
Nền tảng đám mây về tương tác, hình dung và tích hợp dữ liệu.
Một nền tảng dữ liệu đám mây được thiết kế để giúp người dùng tìm kiếm, tương tác, hình dung và chia sẻ dữ liệu. Cho phép tích hợp dữ liệu ngoại vi và nội bộ. Cung cấp cách thiết lập cơ sở hạ tầng để làm sạch, phân tích và hình dung dữ liệu trong ứng dụng web của họ và cung cấp một trung tâm dữ liệu để xem trước, mua và bán dữ liệu.
Để sử dụng nền tảng dữ liệu đám mây, người dùng cần đăng ký một tài khoản và đăng nhập. Sau đó, họ có thể tìm kiếm dữ liệu, tích hợp nguồn dữ liệu ngoại vi và nội bộ, sử dụng các công cụ hạ tầng để làm sạch, phân tích và hình dung dữ liệu, và khám phá trung tâm dữ liệu để xem trước, mua và bán dữ liệu.
Tìm kiếm và khám phá dữ liệu
Tích hợp dữ liệu
Công cụ cơ sở hạ tầng để làm sạch, phân tích và hình dung dữ liệu
Trung tâm dữ liệu để xem trước, mua và bán dữ liệu
Rose AI cung cấp cho bạn Trợ lý Phân tích AI,Khai thác dữ liệu trí tuệ nhân tạo nền tảng dữ liệu đám mây,tích hợp dữ liệu,hình dung dữ liệu,trung tâm dữ liệu,làm sạch dữ liệu,phân tích dữ liệu mà bạn có thể sử dụng cho tất cả các tính năng trí tuệ nhân tạo này.
GPT-powered truy vấn cho dữ liệu thời gian thực trên GitHub.
Data Explorer by OSS Insight là một công cụ truy vấn được cấp nguồn bởi GPT cho khám phá dữ liệu thời gian thực trên GitHub. Chỉ cần đặt câu hỏi của bạn bằng ngôn ngữ tự nhiên, và Data Explorer sẽ tạo ra SQL, truy vấn dữ liệu và hiển thị kết quả một cách trực quan.
Để sử dụng Data Explorer, chỉ cần nhập câu hỏi hoặc truy vấn của bạn bằng ngôn ngữ tự nhiên. Công cụ sẽ tạo ra truy vấn SQL tương ứng và lấy dữ liệu từ GitHub. Kết quả sẽ được hiển thị dưới dạng trực quan để dễ hiểu và phân tích.
Công cụ truy vấn được cấp nguồn GPT
Khám phá dữ liệu thời gian thực trên GitHub
Truy vấn ngôn ngữ tự nhiên
Tạo ra SQL
Hiển thị dữ liệu
OSS Insight cung cấp cho bạn Danh mục Công cụ AI,Khai thác dữ liệu trí tuệ nhân tạo,Công cụ Phát triển AI tidb,mysql,sự kiện github,lưu trữ github,chỉ số github,oss,so sánh oss,phân tích oss,pingcap,công cụ hiểu biết,hiển thị dữ liệu,xếp hạng,xu hướng mà bạn có thể sử dụng cho tất cả các tính năng trí tuệ nhân tạo này.
Trò chuyện với dữ liệu của bạn và đưa ra các chiến lược thông minh.
Dữ liệu theo yêu cầu là một nền tảng được trang bị trí thông minh nhân tạo (AI) cho phép bạn trò chuyện với dữ liệu của bạn (Excel, CSV, PDF, vv). Người dùng có thể dễ dàng trích xuất, phân tích và hình dung dữ liệu, nhận thông tin thời gian thực tức thì và đưa ra các chiến lược kinh doanh được tái thông minh.
Bắt đầu cuộc trò chuyện bằng cách đặt câu hỏi hoặc nhập một chủ đề quan tâm. Tiến hành phân tích kỹ lưỡng câu hỏi của bạn và khám phá nguồn dữ liệu đa dạng. Trích xuất thông tin có giá trị từ nhiều nguồn dữ liệu. Truy xuất dữ liệu phù hợp nhất và tạo ra câu trả lời dưới dạng giao diện thân thiện với người dùng.
Trí tuệ nhân tạo tạo ra việc trích xuất dữ liệu
Phân tích mẫu, xu hướng và các ngoại lệ một cách sâu sắc
Dịch các bộ dữ liệu phức tạp thành biểu đồ hấp dẫn mắt
Các khuyến nghị mang tính hành động
Data On Demand cung cấp cho bạn Trợ lý Phân tích AI,Cơ sở kiến thức trí tuệ nhân tạo,Biểu đồ tri thức AI,Quản lý tri thức trí tuệ nhân tạo,Mô hình Ngôn ngữ Lớn (LLMs),Công cụ nghiên cứu Nền tảng được trang bị trí thông minh nhân tạo,trích xuất dữ liệu,phân tích dữ liệu,hình dung dữ liệu,thông tin thời gian thực,chiến lược kinh doanh mà bạn có thể sử dụng cho tất cả các tính năng trí tuệ nhân tạo này.
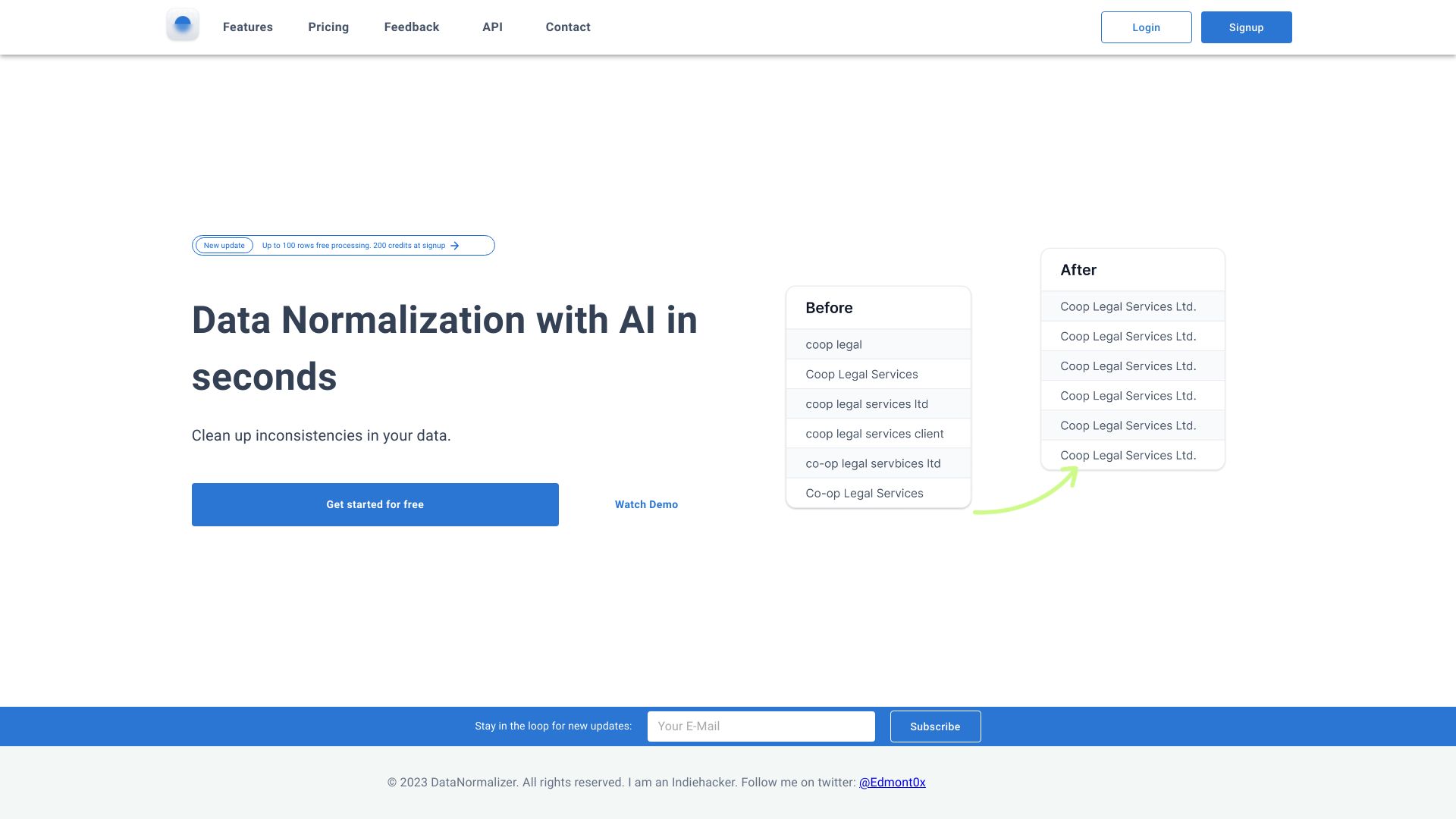
Tiêu chuẩn hóa và chuẩn hóa dữ liệu của bạn chỉ trong vài giây với trí tuệ nhân tạo.
Tiêu chuẩn hóa và chuẩn hóa dữ liệu của bạn trong Excel và CSV
Trình tiêu chuẩn dữ liệu giúp bạn tiêu chuẩn hóa và chuẩn hóa dữ liệu của bạn chỉ trong vài giây với trí tuệ nhân tạo để sửa các lỗi, viết tắt và cách viết không đồng nhất.
Tiêu chuẩn hóa dữ liệu trong Excel, Python, R, SQL, CSV với phù hợp mờ, tìm kiếm mờ và khoảng cách levenshtein.
Data Normalizer cung cấp cho bạn Trợ lý AI SEO,Trợ lý Sáng tạo Quảng cáo AI,Trình tạo quảng cáo AI,Phát triển lãnh đạo AI,Trợ lý Phân tích AI tiêu chuẩn hóa dữ liệu,chuẩn hóa dữ liệu,Excel,CSV,trí tuệ nhân tạo,phù hợp mờ,tìm kiếm mờ,khoảng cách levenshtein mà bạn có thể sử dụng cho tất cả các tính năng trí tuệ nhân tạo này.

Khoa học dữ liệu theo yêu cầu với mức giá cố định hàng tháng.
Mở khóa khoa học dữ liệu theo yêu cầu với Bộ Kit Khoa học Dữ liệu! Tạm biệt việc tuyển dụng khó khăn. Nhận học máy, dự báo và nhiều hơn nữa với một mức giá cố định hàng tháng. Yêu cầu không giới hạn, các giải pháp chất lượng cao và giao hàng nhanh chóng đảm bảo.
Để sử dụng Bộ Kit Khoa học Dữ liệu, đăng ký một trong các gói thành viên của chúng tôi. Sau khi đăng ký, bạn có thể gửi yêu cầu khoa học dữ liệu không giới hạn thông qua nền tảng của chúng tối. Mạng lưới các nhà khoa học dữ liệu chuyên gia của chúng tôi sẽ làm việc trên yêu cầu của bạn và cung cấp các giải pháp chất lượng cao trong vài ngày làm việc. Bạn có thể giao tiếp với nhóm của chúng tôi thông qua kênh giao tiếp không gặp gỡ. Chúng tôi ưu tiên quản lý nhiệm vụ, cho phép bạn xếp hạng yêu cầu của mình và theo dõi tiến trình của chúng. Ngoài ra, bạn có quyền truy cập đầy đủ nhóm, vì vậy toàn bộ nhóm của bạn có thể khởi tạo yêu cầu dữ liệu và cập nhật.
Máy học
Dự báo
Trực quan hóa dữ liệu
Tối ưu hóa
Tư vấn
Xử lý ngôn ngữ tự nhiên
GPT
Tích hợp
Thu thập dữ liệu
Thống kê
Python
Kỹ thuật dữ liệu
Thu thập dữ liệu trang web
Chiến lược
Phân tích do thám
AB Testing
Data Science Kit cung cấp cho bạn Trợ lý Phân tích AI,Biểu đồ AI,Trợ lý Dịch vụ Khách hàng AI,Khai thác dữ liệu trí tuệ nhân tạo,Trình tạo mô tả sản phẩm AI,Phát triển lãnh đạo AI khoa học dữ liệu,máy học,dự báo,trực quan hóa dữ liệu,tối ưu hóa,tư vấn,xử lý ngôn ngữ tự nhiên,mô hình GPT,tích hợp,thu thập dữ liệu,thống kê,Python,kỹ thuật dữ liệu,thu thập dữ liệu trang web,chiến lược,phân tích nguyên nhân,AB testing mà bạn có thể sử dụng cho tất cả các tính năng trí tuệ nhân tạo này.
CDP an toàn và linh hoạt dành cho các doanh nghiệp.
Lytics là nền tảng dữ liệu khách hàng (CDP) linh hoạt và an toàn, dành riêng cho các doanh nghiệp xây dựng công nghệ marketing và quảng cáo.
Lytics cung cấp một giải pháp CDP linh hoạt và theo mô-đun cho phép người dùng quản lý, thống nhất, bổ sung và kích hoạt dữ liệu khách hàng. Với Lytics, người dùng có thể tạo các hồ sơ khách hàng thống nhất, cá nhân hóa chiến dịch tiếp thị, tối ưu hóa chi phí quảng cáo và đưa ra quyết định dựa trên dữ liệu.
Quản lý dữ liệu khách hàng
Thống nhất và bổ sung dữ liệu
Phân đoạn và cá nhân hóa
Tối ưu quảng cáo
Khả năng AI sáng tạo
Tùy chọn triển khai linh hoạt
Lytics Customer Data Platform (CDP) cung cấp cho bạn Trợ lý Quảng cáo AI,Trình tạo trang web AI nền tảng dữ liệu khách hàng,CDP,an toàn,linh hoạt,cấu trúc được xây dựng,marketing,quảng cáo,thống nhất dữ liệu,bổ sung dữ liệu,cá nhân hóa,tối ưu hóa,khả năng AI sáng tạo,quản lý dữ liệu,quảng cáo,tùy chọn triển khai mà bạn có thể sử dụng cho tất cả các tính năng trí tuệ nhân tạo này.
những từ cuối
Bài viết nói về các nền tảng và công cụ khác nhau để tạo dữ liệu tổng hợp để huấn luyện mô hình AI thị giác máy tính. Nó nhấn mạnh tầm quan trọng của dữ liệu huấn luyện được gắn nhãn để phát triển mô hình AI chính xác và đạo đức và giới thiệu một số nền tảng như syntheticAIdata, Incribo, Yadget và MockThis, mỗi nền tảng đều cung cấp các tính năng độc đáo như hình ảnh chân thực như thật, các mô hình 3D đa dạng và giá cả phải chăng. Ngoài ra, nó đề cập đến nền tảng maya.ai của Crayon Data cho cá nhân hóa AI, Julius AI cho phân tích và trực quan hóa dữ liệu và DeepEyes Analytics để đơn giản hóa phân tích dữ liệu cho các dự án Web3. Hơn nữa, nó giới thiệu các trang web cộng đồng như Khoa học Dữ liệu Mở và các nền tảng đám mây như Rose AI cho sự tương tác và trực quan hóa dữ liệu. Cuối cùng, nó giới thiệu các công cụ như Data Explorer để truy vấn dữ liệu trực tiếp từ GitHub và Data on Demand cho phân tích dữ liệu trò chuyện, cũng như các giải pháp như Data Normalizer cho việc chuẩn hóa dữ liệu và Bộ Kit Khoa học Dữ liệu cho các dịch vụ khoa học dữ liệu theo yêu cầu. Những nền tảng và công cụ này phục vụ cho các nhu cầu khác nhau trong cảnh quan AI và khoa học dữ liệu, cung cấp các giải pháp cho việc tạo ra dữ liệu, phân tích, trực quan hóa và cá nhân hóa dữ liệu, trong số các khía cạnh khác nhau.
Giới thiệu về tác giả

I'm an AI Industry Writer, expertly synthesizing tech trends and insights. With a data-driven mind and creative pulse, I translate complex AI concepts into accessible content, engaging industry professionals and enthusiasts alike.
Thêm công cụ AI
- 8 Creative Ways to Use AI Image Generators in Your Projects
- 15 Mind-Blowing AI Art Generators You Need to Try
- 7 Incredible Ways AI Generators Are Revolutionizing Content Creation
- 13 Essential Elements of a Winning Marketing Plan
- 7 Tips for Crafting the Perfect Profile Picture or Avatar
- 13 Essential Tips for Mastering Movie Script Writing
Đặc sắc*

 21.36% 33.83%
21.36% 33.83%
 25.57%
25.57% 14.73% 100.00%
14.73% 100.00%